Ability of machine-learning based clinical decision support system to reduce alert fatigue, wrong-drug errors, and alert users about look alike, sound alike medication

|
- This study sought to evaluate the overall performance of a machine learning-based CDSS (MedGuard) for triggering clinically relevant alerts, acceptance rate, and to intercept inappropriate drug errors as well as LASA drug errors.
- An expert pharmacist checked the suitability of the alerts, rate of acceptance, wrong-drug errors, and confusing drug pairs.
- Over the two-year study period, 1,206,895 prescriptions were ordered and a total of 28,536 alerts were triggered (alert rate: 2.36%). The rate of drug error interception was 1.64% (470 intercepted errors out of 28,536 alerts), which equates to 16.4 intercepted errors per 1000 alerted orders.
- This study shows that machine learning based CDSS, MedGuard, has an ability to improve patients’ safety by triggering clinically valid alerts. Moreover, high acceptance of alert rates can help reduce clinician burnout and adverse events.
Background and objective
The overall benefits of using clinical decision support systems (CDSSs) can be restrained if physicians inadvertently ignore clinically useful alerts due to “alert fatigue” caused by an excessive number of clinically irrelevant warnings. Moreover, inappropriate drug errors, look-alike/sound-alike (LASA) drug errors, and problem list documentation are common, costly, and potentially harmful. This study sought to evaluate the overall performance of a machine learning-based CDSS (MedGuard) for triggering clinically relevant alerts, acceptance rate, and to intercept inappropriate drug errors as well as LASA drug errors.
Methods
We conducted a retrospective study that evaluated MedGuard alerts, the alert acceptance rate, and the rate of LASA alerts between July 1, 2019, and June 31, 2021, from outpatient settings at an academic hospital. An expert pharmacist checked the suitability of the alerts, rate of acceptance, wrong-drug errors, and confusing drug pairs.
Results
Over the two-year study period, 1,206,895 prescriptions were ordered and a total of 28,536 alerts were triggered (alert rate: 2.36%). Of the 28,536 alerts presented to physicians, 13,947 (48.88%) were accepted. A total of 8,014 prescriptions were changed/modified (28.08%, 8,014/28,534) with the most common reasons being adding and/or deleting diseases (52.04%, 4,171/8,014), adding and/or deleting drugs (21.89%, 1,755/8,014) and others (35.48%, 2,844/ 8,014). However, the rate of drug error interception was 1.64% (470 intercepted errors out of 28,536 alerts), which equates to 16.4 intercepted errors per 1000 alerted orders.
Conclusion
This study shows that machine learning based CDSS, MedGuard, has an ability to improve patients’ safety by triggering clinically valid alerts. This system can also help improve problem list documentation and intercept inappropriate drug errors and LASA drug errors, which can improve medication safety. Moreover, high acceptance of alert rates can help reduce clinician burnout and adverse events.
The overall benefits of using clinical decision support systems (CDSSs) can be restrained if physicians inadvertently ignore clinically useful alerts due to “alert fatigue” caused by an excessive number of clinically irrelevant warnings. Moreover, inappropriate drug errors, look-alike/sound-alike (LASA) drug errors, and problem list documentation are common, costly, and potentially harmful. This study sought to evaluate the overall performance of a machine learning-based CDSS (MedGuard) for triggering clinically relevant alerts, acceptance rate, and to intercept inappropriate drug errors as well as LASA drug errors.
Methods
We conducted a retrospective study that evaluated MedGuard alerts, the alert acceptance rate, and the rate of LASA alerts between July 1, 2019, and June 31, 2021, from outpatient settings at an academic hospital. An expert pharmacist checked the suitability of the alerts, rate of acceptance, wrong-drug errors, and confusing drug pairs.
Results
Over the two-year study period, 1,206,895 prescriptions were ordered and a total of 28,536 alerts were triggered (alert rate: 2.36%). Of the 28,536 alerts presented to physicians, 13,947 (48.88%) were accepted. A total of 8,014 prescriptions were changed/modified (28.08%, 8,014/28,534) with the most common reasons being adding and/or deleting diseases (52.04%, 4,171/8,014), adding and/or deleting drugs (21.89%, 1,755/8,014) and others (35.48%, 2,844/ 8,014). However, the rate of drug error interception was 1.64% (470 intercepted errors out of 28,536 alerts), which equates to 16.4 intercepted errors per 1000 alerted orders.
Conclusion
This study shows that machine learning based CDSS, MedGuard, has an ability to improve patients’ safety by triggering clinically valid alerts. This system can also help improve problem list documentation and intercept inappropriate drug errors and LASA drug errors, which can improve medication safety. Moreover, high acceptance of alert rates can help reduce clinician burnout and adverse events.
Chun‑You Chen, Ya-Lin Chen, Jeremiah Scholl, Hsuan-Chia Yang, Yu-Chuan Jack Li, Ability of machine-learning based clinical decision support system to reduce alert fatigue, wrong-drug errors, and alert users about look alike, sound alike medication, Computer Methods and Programs in Biomedicine, 2023, 107869
Reveal irAE by analysis of 197,921 claim-based prescriptions

|
Background
Immune-related adverse effects (irAE) are widely known for immune checkpoint inhibitors (ICI), but medications used to relieve irAE based on patient profile and condition are not offered in guidelines. Publications are available to reveal irAE from hospitals, but the number of cases are normally only a few hundred and insufficient to stratify by more variables. Claim-based data points were also used in a few publications, based on analysis of diagnosis code such as ICD-9 and ICD-10. However, missing or wrong coding of adverse effects are well-known and over-exaggerated for severe adverse events, and are also affected by reimbursement policy. This research used medications from a large national health system to understand irAE and treatments related to them.
Methods
2017-2019 National Health Insurance database (NHIDB) in Taiwan was used. The case group was identified as (2,474) patients who used PD-1 inhibitors (more specifically Nivolumab, Pembrolizumab, and Atezolizumab because only those three were available in the duration). A control group was identified as (6,207) patients given platinum-based chemotherapy (cases using other cancer drugs at the same time were excluded). Odds ratios were calculated to see frequency of irAE and medications in both groups.
Results
Top 10 medications are listed. Diphenhydramine and pain killers were the most common AE-relief medications for cancer patients in NHIDB and only anilides (mostly propacetamol) are overlapped. The rest of the drugs with OR > 3, especially steroids (thyroid and corticosteroids), were used mainly for irAE.
Conclusions
The research reveals a novel approach to understand how physicians prescribe to treat irAE. The larger number of cases reported compared to previous studies suggests that such a database can be used for future research, including to reveal demographic patterns, and to aid the development of guidelines, teaching aids, and decision support.
Immune-related adverse effects (irAE) are widely known for immune checkpoint inhibitors (ICI), but medications used to relieve irAE based on patient profile and condition are not offered in guidelines. Publications are available to reveal irAE from hospitals, but the number of cases are normally only a few hundred and insufficient to stratify by more variables. Claim-based data points were also used in a few publications, based on analysis of diagnosis code such as ICD-9 and ICD-10. However, missing or wrong coding of adverse effects are well-known and over-exaggerated for severe adverse events, and are also affected by reimbursement policy. This research used medications from a large national health system to understand irAE and treatments related to them.
Methods
2017-2019 National Health Insurance database (NHIDB) in Taiwan was used. The case group was identified as (2,474) patients who used PD-1 inhibitors (more specifically Nivolumab, Pembrolizumab, and Atezolizumab because only those three were available in the duration). A control group was identified as (6,207) patients given platinum-based chemotherapy (cases using other cancer drugs at the same time were excluded). Odds ratios were calculated to see frequency of irAE and medications in both groups.
Results
Top 10 medications are listed. Diphenhydramine and pain killers were the most common AE-relief medications for cancer patients in NHIDB and only anilides (mostly propacetamol) are overlapped. The rest of the drugs with OR > 3, especially steroids (thyroid and corticosteroids), were used mainly for irAE.
Conclusions
The research reveals a novel approach to understand how physicians prescribe to treat irAE. The larger number of cases reported compared to previous studies suggests that such a database can be used for future research, including to reveal demographic patterns, and to aid the development of guidelines, teaching aids, and decision support.
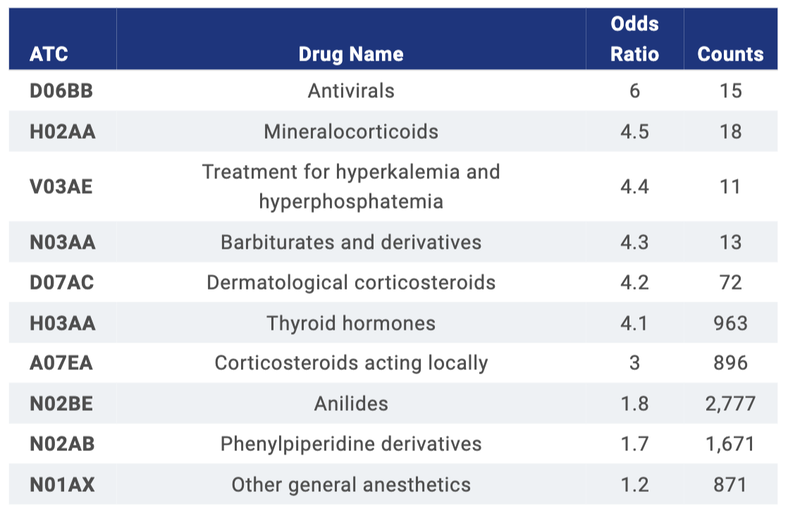
Odds ratio of medications used in both ICI and chemo-drugs for irAE
Jeremiah Gordon Scholl, An Jim Long, Yu-Chuan (Jack) Li, Reveal irAE by analysis of 197,921 claim-based prescriptions,
Journal of Clinical Oncology , 41, 2023 (suppl 16; abstr e13639)
Journal of Clinical Oncology , 41, 2023 (suppl 16; abstr e13639)
DeepDRG: Performance of Artificial Intelligence Model for Real-Time Prediction of Diagnosis-Related Groups
|
|
|
The use of diagnosis-related groups (DRGs) has been increased to claim reimbursement for inpatient care. The overall benefits of using DRGs depend upon the accuracy of clinical coding to obtain reasonable reimbursement. However, the selection of appropriate codes is always challenging and requires professional expertise. The rate of incorrect DRGs is always high due to the heavy workload, poor quality of documentation, and lack of computer assistance. We therefore developed deep learning (DL) models to predict the primary diagnosis for appropriate reimbursement and improving hospital performance.
Healthcare spending has consistently been increasing globally. Inpatient care is one of the most expensive hospital services, accounting for approximately 31% of the total expenditure. With the limited resources and increased complexity, policymakers are facing immense challenges of reducing health care costs while improving financial protections, high-quality care, and lowering out-of-pocket (OOP) costs for people. The Fee-for-service (FFS) is a basic payment system for both national and private hospitals in which all care providers are reimbursed for each service provided. To rein in excessive healthcare costs and maintain sustainable procedures for inpatients, prospective payment policies are often implemented to foster risk-sharing between insurers and providers. Nowadays, the governments of several countries have already reformed their hospital payment policy by shifting from FFS to diagnosis related groups (DRGs).
The concept of DRGs has now been widely adopted and become the principal means of reimbursement for inpatient services globally. Previous studies have shown that the implementation of DRGs helped to shorten the length of hospital stays and lower OOP by efficiently allocating hospital resources. DRGs, a prospective payment system, are used to effectively classify and combine diseases with similar characteristics into different diagnostics and treatment groups. Indeed, DRGs are set to achieve greater equality of financing based on the homogeneity of the clinical process and the similarity of resource consumption. The diagnostics codes should be accurately matched with DRGs codes to claim actual reimbursement, but this is a time‐consuming process and requires expert knowledge to manually retrieve information from patients’ clinical records. Selection of appropriate DRGs codes depends on several factors, such as patients’ comorbidities, complications, treatments, age, discharge status, and the principal diagnoses provided by physicians. Therefore, the quality of DRGs coding is a key factor that influences a hospital’s ability to receive reasonable reimbursement and its overall profits.
DRGs coding errors can influence hospitals’ income, hamper proper planning, and often lead to unfair distributions of resources. Ayub et al. evaluated coding accuracy and its impact on hospital costs, reporting 9.6% miscoding with a total lost billing opportunity of $587,799. Cheng et al. reviewed the causes and consequences of miscoding in a Melbourne tertiary hospital, finding that 16% of the 752 cases audited reflected a DRG change and caused a loss of hospital revenue of nearly AUD 575,300.
Furthermore, the incorrect selection of the principal diagnosis accounted for an additional13% of the DRG changes, which is due to the poor quality of documentation. A previous study demonstrated that the overall rate of incorrect DRGs coding was up to 52%, which may be due to a lack of professional experience, workload, and lack of automation.
The widespread application of electronic health records (EHRs) has generated large amounts of patient data and created immense opportunities to predict the primary diagnosis using deep learning (DL). In this study, we developed and validated DL models to predict the primary diagnosis for appropriate reimbursement and improve the quality of care.
A dataset consisting of 81,486 patients with 128,105 episodes was used for model training and testing. Patients’ age, sex, drugs, diseases, laboratory tests, procedures, and operation history were used as inputs to our multiclass prediction model. Gated recurrent unit (GRU) and artificial neural network (ANN) models were developed to predict 200 primary diagnoses. The performance of the DL models was measured by the area under the receiver operating curve, precision, recall, and F1 score. Of the two DL models, the GRU method, had the best performance in predicting the primary diagnosis (AUC: 0.99, precision: 83.2%, and recall: 66.0%).
However, the performance of ANN model for DRGs prediction achieved AUC of 0.99 with a precision of 0.82 and recall of 0.57. The findings of our study show that DL algorithms, especially GRU, can be used to develop DRGs prediction models for identifying primary diagnosis accurately. DeepDRGs would help to claim appropriate financial incentives, enable proper utilization of medical resources, and improve hospital performance.
The concept of DRGs has now been widely adopted and become the principal means of reimbursement for inpatient services globally. Previous studies have shown that the implementation of DRGs helped to shorten the length of hospital stays and lower OOP by efficiently allocating hospital resources. DRGs, a prospective payment system, are used to effectively classify and combine diseases with similar characteristics into different diagnostics and treatment groups. Indeed, DRGs are set to achieve greater equality of financing based on the homogeneity of the clinical process and the similarity of resource consumption. The diagnostics codes should be accurately matched with DRGs codes to claim actual reimbursement, but this is a time‐consuming process and requires expert knowledge to manually retrieve information from patients’ clinical records. Selection of appropriate DRGs codes depends on several factors, such as patients’ comorbidities, complications, treatments, age, discharge status, and the principal diagnoses provided by physicians. Therefore, the quality of DRGs coding is a key factor that influences a hospital’s ability to receive reasonable reimbursement and its overall profits.
DRGs coding errors can influence hospitals’ income, hamper proper planning, and often lead to unfair distributions of resources. Ayub et al. evaluated coding accuracy and its impact on hospital costs, reporting 9.6% miscoding with a total lost billing opportunity of $587,799. Cheng et al. reviewed the causes and consequences of miscoding in a Melbourne tertiary hospital, finding that 16% of the 752 cases audited reflected a DRG change and caused a loss of hospital revenue of nearly AUD 575,300.
Furthermore, the incorrect selection of the principal diagnosis accounted for an additional13% of the DRG changes, which is due to the poor quality of documentation. A previous study demonstrated that the overall rate of incorrect DRGs coding was up to 52%, which may be due to a lack of professional experience, workload, and lack of automation.
The widespread application of electronic health records (EHRs) has generated large amounts of patient data and created immense opportunities to predict the primary diagnosis using deep learning (DL). In this study, we developed and validated DL models to predict the primary diagnosis for appropriate reimbursement and improve the quality of care.
A dataset consisting of 81,486 patients with 128,105 episodes was used for model training and testing. Patients’ age, sex, drugs, diseases, laboratory tests, procedures, and operation history were used as inputs to our multiclass prediction model. Gated recurrent unit (GRU) and artificial neural network (ANN) models were developed to predict 200 primary diagnoses. The performance of the DL models was measured by the area under the receiver operating curve, precision, recall, and F1 score. Of the two DL models, the GRU method, had the best performance in predicting the primary diagnosis (AUC: 0.99, precision: 83.2%, and recall: 66.0%).
However, the performance of ANN model for DRGs prediction achieved AUC of 0.99 with a precision of 0.82 and recall of 0.57. The findings of our study show that DL algorithms, especially GRU, can be used to develop DRGs prediction models for identifying primary diagnosis accurately. DeepDRGs would help to claim appropriate financial incentives, enable proper utilization of medical resources, and improve hospital performance.
Islam MM, Li G-H, Poly TN, Li Y-C. DeepDRG: Performance of Artificial Intelligence Model for Real-Time Prediction of Diagnosis-Related Groups. Healthcare. 2021; 9(12):1632.
Improved diagnosis-medication association mining to reduce pseudo-associations
|
|

|
Association rule mining has been adopted to medical fields to discover prescribing patterns or relationships among diseases and/or medications; however, it has generated unreasonable associations among these entities. This study aims to identify the real-world profile of disease-medication (DM) associations using the modified mining algorithm and assess its performance in reducing DM pseudo-associations.
We retrieved data from outpatient records between January 2011 and December 2015 in claims databases maintained by the Health and Welfare Data Science Center, Ministry of Health and Welfare, Taiwan. The association rule mining's lift (Q-value) was adopted to quantify DM associations, referred to as Q1 for the original algorithm and as Q2 for the modified algorithm. One thousand DM pairs with positive Q1-values (Q1+) and negative or no Q2-values (Q2- or Q2∅) were selected as the validation dataset, in which two pharmacists assessed the DM associations.
A total of 3,120,449 unique DM pairs were identified, of which there were 333,347 Q1+Q2- pairs and 429,931 Q1+Q2∅ pairs. Q1+Q2- rates were relatively high in ATC classes C (29.91%) and R (30.24%). Classes L (69.91%) and V (52.52%) demonstrated remarkably high Q1+Q2∅ rates. For the 1000 pairs in the validation, 93.7% of the Q1+Q2- or Q1+Q2∅ DM pairs were assessed as pseudo-associations. However, classes M (5.3%), H (4.5%), and B (4.1%) showed the highest rates of plausible associations falsely given Q2- or Q2∅ by the modified algorithm.
The modified algorithm demonstrated high accuracy to identify pseudo-associations regarded as positive associations by the original algorithm and would potentially be applied to improve secondary databases to facilitate research on real-world prescribing patterns and further enhance drug safety.
A total of 3,120,449 unique DM pairs were identified, of which there were 333,347 Q1+Q2- pairs and 429,931 Q1+Q2∅ pairs. Q1+Q2- rates were relatively high in ATC classes C (29.91%) and R (30.24%). Classes L (69.91%) and V (52.52%) demonstrated remarkably high Q1+Q2∅ rates. For the 1000 pairs in the validation, 93.7% of the Q1+Q2- or Q1+Q2∅ DM pairs were assessed as pseudo-associations. However, classes M (5.3%), H (4.5%), and B (4.1%) showed the highest rates of plausible associations falsely given Q2- or Q2∅ by the modified algorithm.
The modified algorithm demonstrated high accuracy to identify pseudo-associations regarded as positive associations by the original algorithm and would potentially be applied to improve secondary databases to facilitate research on real-world prescribing patterns and further enhance drug safety.
Wang CH, Nguyen PA, Jack Li YC, Islam MM, Poly TN, Tran QV, Huang CW, Yang HC. Improved diagnosis-medication association mining to reduce pseudo-associations. Computer Methods and Programs in Biomedicine. 2021 Aug;207:106181.
Assessing the International Transferability of a Machine Learning Model for Detecting Medication Error in the General Internal Medicine Clinic: Multicenter Preliminary Validation Study
|
|

|
Previously, we had developed a machine learning (ML) model based on Taiwan’s local databases (TLD) to address this issue. However, the international transferability of this model is unclear. This study examines the international transferability of a machine learning model for detecting medication errors and whether the federated learning approach could further improve the accuracy of the model.
Medication errors are a major contributor to morbidity and mortality. Although the exact number of deaths related to medical errors is still under debate, the To Err Is Human report estimated that the figure might be approximately 44,000 to 98,000 per year in the United States alone. Medication errors also result in excess health care–related costs, which are estimated at more than US $20 billion per year in the United States.
Preventable adverse drug events (ADEs) also appear to be common not only in the hospital but also in the ambulatory setting, with one estimate amounting to US $1.8 billion annually for treating them. Reducing medication errors is crucial to enhance health care quality and improve patient safety. However, considering the time and cost needed, it is impossible for hospitals to double-check every prescription made by every physician in real time.
To combat this problem, studies have shown that health information technology (IT) presents a viable solution . Among all IT tools, clinical decision support systems that can provide real-time alerts have demonstrated perhaps more effective in helping physicians to prevent medication errors. However, the impact of these applications has been variable. In addition, the vast majority of the currently deployed alert systems are rule based, which means that they have explicitly coded logic written to identify medication errors. However, these rule-based systems are generally set to go off too frequently because of the lack of adaptability in clinical practice, leading to alert fatigue, which in turn can increase ADE rates.
Machine learning (ML) has shown promising results in medicine and health care, especially in relation to clinical documentation and prescription prediction. Unsupervised learning, which is a type of ML algorithm used to establish relationships within data sets without labels, combined with a well-curated and large data set of prescriptions has the potential to generate algorithmic models to minimize prescription errors. Previously, we had presented an ML model that evaluated whether a prescription was explicitly substantiated (by way of diagnosis or other medications) and prevented medication errors from occurring. The model was named as the appropriateness of prescription (AOP) model. It contained disease-medication (D-M) associations and medication-medication (M-M) associations that were identified through unsupervised association rule learning.
These associations were generated based on prescription data from Taiwan’s local databases (TLD), which had collected health information from nearly the entire Taiwanese population (about 23 million people) for over 20 years. The AOP model has been validated in 5 Taiwanese hospitals and continues to have high accuracy (over 80%) and high sensitivity (80%-96%), highlighting the model’s potential to have a true clinical impact.
As physicians in Taiwan are educated with the same evidence-based guidelines as physicians in the United States, in theory, the experience-based ML model generated from TLD could be transferable to US clinical practice. However, there is no validation study that examines the transferability of the TLD-developed ML model in US health care systems. Although there are a few research studies demonstrating the feasibility of transferring ML models across health care institutions, one of the major challenges to the transferability of ML models in health care is that most of these models are trained using single-site data sets that may be insufficiently large or diverse.
Recently, federated learning has become an emerging technique to address the issues of isolated data islands and privacy, in which each distinct data federate trains their own model with their own data before all the federates aggregate their results. In our study, we undertook a cross-national multicenter study to validate the performance of the AOP model in detecting the explicit substantiation of prescriptions using an enriched data set from the electronic health record (EHR) system of Brigham Women’s Hospital (BWH) and Massachusetts General Hospital (MGH). Both are Harvard Medical School teaching hospitals. To the best of our knowledge, this is the first cross-national multicenter study to examine the transferability of an ML model for the detection of medication errors. Detailed analyses were conducted to evaluate the effectiveness of the AOP model, and a federated learning approach was applied to explore the potential to construct a model with better performance using cross-national data sets.
Preventable adverse drug events (ADEs) also appear to be common not only in the hospital but also in the ambulatory setting, with one estimate amounting to US $1.8 billion annually for treating them. Reducing medication errors is crucial to enhance health care quality and improve patient safety. However, considering the time and cost needed, it is impossible for hospitals to double-check every prescription made by every physician in real time.
To combat this problem, studies have shown that health information technology (IT) presents a viable solution . Among all IT tools, clinical decision support systems that can provide real-time alerts have demonstrated perhaps more effective in helping physicians to prevent medication errors. However, the impact of these applications has been variable. In addition, the vast majority of the currently deployed alert systems are rule based, which means that they have explicitly coded logic written to identify medication errors. However, these rule-based systems are generally set to go off too frequently because of the lack of adaptability in clinical practice, leading to alert fatigue, which in turn can increase ADE rates.
Machine learning (ML) has shown promising results in medicine and health care, especially in relation to clinical documentation and prescription prediction. Unsupervised learning, which is a type of ML algorithm used to establish relationships within data sets without labels, combined with a well-curated and large data set of prescriptions has the potential to generate algorithmic models to minimize prescription errors. Previously, we had presented an ML model that evaluated whether a prescription was explicitly substantiated (by way of diagnosis or other medications) and prevented medication errors from occurring. The model was named as the appropriateness of prescription (AOP) model. It contained disease-medication (D-M) associations and medication-medication (M-M) associations that were identified through unsupervised association rule learning.
These associations were generated based on prescription data from Taiwan’s local databases (TLD), which had collected health information from nearly the entire Taiwanese population (about 23 million people) for over 20 years. The AOP model has been validated in 5 Taiwanese hospitals and continues to have high accuracy (over 80%) and high sensitivity (80%-96%), highlighting the model’s potential to have a true clinical impact.
As physicians in Taiwan are educated with the same evidence-based guidelines as physicians in the United States, in theory, the experience-based ML model generated from TLD could be transferable to US clinical practice. However, there is no validation study that examines the transferability of the TLD-developed ML model in US health care systems. Although there are a few research studies demonstrating the feasibility of transferring ML models across health care institutions, one of the major challenges to the transferability of ML models in health care is that most of these models are trained using single-site data sets that may be insufficiently large or diverse.
Recently, federated learning has become an emerging technique to address the issues of isolated data islands and privacy, in which each distinct data federate trains their own model with their own data before all the federates aggregate their results. In our study, we undertook a cross-national multicenter study to validate the performance of the AOP model in detecting the explicit substantiation of prescriptions using an enriched data set from the electronic health record (EHR) system of Brigham Women’s Hospital (BWH) and Massachusetts General Hospital (MGH). Both are Harvard Medical School teaching hospitals. To the best of our knowledge, this is the first cross-national multicenter study to examine the transferability of an ML model for the detection of medication errors. Detailed analyses were conducted to evaluate the effectiveness of the AOP model, and a federated learning approach was applied to explore the potential to construct a model with better performance using cross-national data sets.
Chin YPH, Song W, Lien CE, Yoon CH, Wang W, Liu J, Nguyen PA, Feng YT, Zhou L, Li YCJ, Bates DW, Assessing the International Transferability of a Machine Learning Model for Detecting Medication Error in the General Internal Medicine Clinic: Multicenter Preliminary Validation Study. JMIR Med Inform 2021;9(1):e23454
A Probabilistic Model for Reducing Medication Errors: A Sensitivity Analysis using data in Electronic Health Records
|
|

|
Succeeded performing the analysis of a probabilistic model for reducing medication errors with various thresholds. Picking the optimal threshold is both an art and a science — it should be done with careful reference to both specialties and the purpose of the application. The AESOP model was observed over 80% accurate (accuracy) for overall departments. Inappropriate prescriptions were determined with a lower rate (i.e. 1%–3%) and the positive predictive value (PPV) ranged from 40%−60%.
Medication-related clinical decision support systems have already been considered as a sophisticated method to improve healthcare quality, however, its importance has not been fully recognized. This paper’s aim was to validate an existing probabilistic model that can automatically identify medication errors by performing a sensitivity analysis from electronic medical record data.
773.4 million prescriptions were employed to compute the disease-medication and medication-medication associations. We built a knowledge base that consisted of 2.22 million disease-medication (DM) and 0.78 million medication-medication (MM) associations.
We collected 626,710 prescriptions from outpatient visit prescriptions from six departments (Cardiovascular, Neurology, Metabolism, Gastroenterology, Ophthalmology, and Urology department) across five hospitals in Taiwan.
We implemented the AESOP model for all 625,710 prescriptions using various threshold (α); the α is ranged from 0.5 to 1.5. Subsequently, 400 prescriptions with their default threshold of 1 that were randomly selected from each department, were evaluated by three certified physicians by their specialty. In total, 2400 prescriptions (400 per department) were evaluated by 18 physicians (three physicians per department) in our study.
Validation against the gold standard showed a high accuracy (over 80%), sensitivity (80–96%), and positive predictive value (over 85%). The negative predictive values ranged from 45 to 75%. PPV (positive predictive values) means both AESOP model prediction and experts evaluate the prescription as appropriate. NPV (negative predictive values) means both AESOP model prediction and experts evaluate the prescription as inappropriate.
We performed sensitivity analysis and validated the AESOP model at different hospital sites. Our findings show that picking up the optimal threshold of the model would be different in departments and depends on the purpose of the applications. Building an innovative system for detecting medication errors has many potential benefits for patient safety, improving quality healthcare, and conducting research.
773.4 million prescriptions were employed to compute the disease-medication and medication-medication associations. We built a knowledge base that consisted of 2.22 million disease-medication (DM) and 0.78 million medication-medication (MM) associations.
We collected 626,710 prescriptions from outpatient visit prescriptions from six departments (Cardiovascular, Neurology, Metabolism, Gastroenterology, Ophthalmology, and Urology department) across five hospitals in Taiwan.
We implemented the AESOP model for all 625,710 prescriptions using various threshold (α); the α is ranged from 0.5 to 1.5. Subsequently, 400 prescriptions with their default threshold of 1 that were randomly selected from each department, were evaluated by three certified physicians by their specialty. In total, 2400 prescriptions (400 per department) were evaluated by 18 physicians (three physicians per department) in our study.
Validation against the gold standard showed a high accuracy (over 80%), sensitivity (80–96%), and positive predictive value (over 85%). The negative predictive values ranged from 45 to 75%. PPV (positive predictive values) means both AESOP model prediction and experts evaluate the prescription as appropriate. NPV (negative predictive values) means both AESOP model prediction and experts evaluate the prescription as inappropriate.
We performed sensitivity analysis and validated the AESOP model at different hospital sites. Our findings show that picking up the optimal threshold of the model would be different in departments and depends on the purpose of the applications. Building an innovative system for detecting medication errors has many potential benefits for patient safety, improving quality healthcare, and conducting research.
Huang, C. Y., Nguyen, P. A., Yang, H. C., Islam, M. M., Liang, C. W., Lee, F. P., & Li, Y. C. (2019). A probabilistic model for reducing medication errors: A sensitivity analysis using Electronic Health Records data. Computer Methods and Programs in Biomedicine, 170, 31-38.
A Probabilistic Model for Reducing Medication Errors
|
|
|
The AOP model has a variety of applications. It can be used to alert physicians if medication errors are detected while prescribing medications using the CPOE system. Additionally, the model could be used to reduce the size of medication list in the CPOE for a given diagnosis. An automated medication listing systems and clinical decision support system (CDSS) can also be developed by using the AOP model.
We developed a model to detect uncommon or rare medication for a given disease when ordering prescriptions based on disease-medication associations.
This study focuses on medication-disease relationships by applying the association rule mining, and using statistical methods to detect medication errors in the computerized physician order entry (CPOE) systems in order to improve patient’s safety. 103.5 million prescriptions with 204.5 million diagnosis ICD9-CM (International Classification of Disease v.9-Clinical Modification) codes and 347.7 million medications with the Taiwan NHI codes were used in the analysis.
We use Q values to compute association for Disease-medication (DM) and Medication-medication (MM). Q value is the ratio between the joint probability of disease-medication and medication-medication with respect to their expected probability under the independent assumption known as lift (interest) and relative risk (RR) in similar studies dealing with associations. A total of 1.34 million DM and 0.65 million MM pairs with their Q values were computed from 103.5 million prescriptions.
Then we develop a model that can automatically evaluate the Appropriateness of a Prescription (AOP) which is developed based upon following rules:
Finally, we test the model for 100,000 randomly selected prescriptions, and then validating the results using seven human experts. The results showed 96% accuracy for appropriate and 45% accuracy for inappropriate prescriptions, with a sensitivity and specificity of 75.9% and 89.5%, respectively.
We successfully developed, tested, and validated the AOP model, which is able to predict and identify the appropriateness of the prescriptions. The AOP model developed in this study is able to detect accurately the inappropriate medications prescribed via COPE system. Thus, the PPV of the validation results from both physicians and pharmacists were accurate for the appropriate prescriptions. Moreover, this model could be applied in clinical practice to aid in improving prescription appropriateness, accuracy, patient safety, and patient care.
This study focuses on medication-disease relationships by applying the association rule mining, and using statistical methods to detect medication errors in the computerized physician order entry (CPOE) systems in order to improve patient’s safety. 103.5 million prescriptions with 204.5 million diagnosis ICD9-CM (International Classification of Disease v.9-Clinical Modification) codes and 347.7 million medications with the Taiwan NHI codes were used in the analysis.
We use Q values to compute association for Disease-medication (DM) and Medication-medication (MM). Q value is the ratio between the joint probability of disease-medication and medication-medication with respect to their expected probability under the independent assumption known as lift (interest) and relative risk (RR) in similar studies dealing with associations. A total of 1.34 million DM and 0.65 million MM pairs with their Q values were computed from 103.5 million prescriptions.
Then we develop a model that can automatically evaluate the Appropriateness of a Prescription (AOP) which is developed based upon following rules:
- The number of positive DMQs and positive MMQs should be greater than or equal to the number of medications.
- All diagnoses should have at least one positive DMQ.
- Each medication should have at least one positive DMQ or positive MMQ.
Finally, we test the model for 100,000 randomly selected prescriptions, and then validating the results using seven human experts. The results showed 96% accuracy for appropriate and 45% accuracy for inappropriate prescriptions, with a sensitivity and specificity of 75.9% and 89.5%, respectively.
We successfully developed, tested, and validated the AOP model, which is able to predict and identify the appropriateness of the prescriptions. The AOP model developed in this study is able to detect accurately the inappropriate medications prescribed via COPE system. Thus, the PPV of the validation results from both physicians and pharmacists were accurate for the appropriate prescriptions. Moreover, this model could be applied in clinical practice to aid in improving prescription appropriateness, accuracy, patient safety, and patient care.
Nguyen, P. A., Syed-Abdul, S., Iqbal, U., Hsu, M. H., Huang, C. L., Li, H. C., Li, Y. C. J. (2013). A Probabilistic Model for Reducing Medication Errors. PloS one, 8(12).
Related Papers
- Huang, C. Y., Nguyen, P. A. A., Clinciu, D. L., Hsu, C. K., Lu, J. C. R., Yang, H. C., Li, Y. C. J. (2017). A personalized medication management platform (PMMP) to improve medication adherence: A randomized control trial. Computer Methods and Programs in Biomedicine, 140, 275-281.
- Li, Y. C., Yen, J. C., Chiu, W. T., Jian, W. S., Syed-Abdul, S., & Hsu, M. H. (2015). Building a National Electronic Medical Record Exchange System - Experiences in Taiwan. Computer Methods and Programs in Biomedicine, 121(1), 14-20.
- Syed-Abdul, S., Moldovan, M., Nguyen, P. A., Enikeev, R., Jian, W. S., Iqbal, U., Li, Y. C. (2015). Profiling phenome-wide associations: a population-based observational study. Journal of the American Medical Informatics Association, 22(4), 896-899.
- Syed-Abdul, S., Nguyen, A., Huang, F., Jian, W. S., Iqbal, U., Yang, V., Li, Y. C. (2014). A smart medication recommendation model for the electronic prescription. Computer Methods and Programs in Biomedicine, 117(2), 218-224.
- Yeh, M. L., Chang, Y. J., Wang, P. Y., Li, Y. C., & Hsu, C. Y. (2013). Physicians' responses to computerized drug-drug interaction alerts for outpatients. Computer Methods and Programs in Biomedicine, 111(1), 17-25.
- Chang, Y. J., Yeh, M. L., Li, Y. C., Hsu, C. Y., Yen, Y. T., Wang, P. Y., & Chu, T. W. (2011). Potential drug interactions in dermatologic outpatient prescriptions-experience from nationwide population-based study in Taiwan. Dermatologica Sinica, 29(3), 81-85.
- Hsu, M. H., Yen, J. C., Chiu, W. T., Tsai, S. L., Liu, C. T., & Li, Y. C. (2011). Using Health Smart Cards to Check Drug Allergy History: The Perspective from Taiwan's Experiences. Journal of Medical Systems, 35(4), 555-558.
- Long, A. J., Chang, P., Li, Y. C., & Chiu, W. T. (2008). The use of a CPOE log for the analysis of physicians' behavior when responding to drug-duplication reminders. International Journal of Medical Informatics, 77(8), 499-506.
- Li, Y. C., Haug, P., Lincoln, M., Turner, C., Pryor, T., & Warner, H. (1995). Assessing the behavioral impact of a diagnostic decision support system. Paper presented at the Proceedings of the Annual Symposium on Computer Application in Medical Care.
- Li, Y. C., Haug, P. J., & Warner, H. R. (1994). Automated Transformation Of Probabilistic Knowledge For A Medical Diagnostic System. Journal Of The American Medical Informatics Association, 765-769.



